

What’s happened? Google has announced the rollout of Gemini 3, stating it is its most capable and intelligent AI model yet. The model handles text, images, and audio simultaneously, meaning you could show a photo, ask about it, and hear or read a detailed answer, all in one go. It’s also available immediately in the Gemini app for Pro users and is being integrated into Google Search.
- Gemini 3 Pro is described by Google as “natively multimodal,” supporting tasks like turning recipe photos into full cookbooks or generating interactive study tools from video lectures.
- Google says the model has improved reasoning capabilities, better task-planning, and reduced “sycophancy” (i.e., less flattery and more direct answers) compared to past versions.
- The launch comes with new tools like Google’s Antigravity coding platform, which uses Gemini 3 Pro to automate workflows and document every step via artifacts.
Why this is important: This launch signals a major shift in how we might interact with AI. With Gemini 3’s multimodal ability, you’re no longer limited to typing questions. Instead, you can show images, talk to it, and play audio, all in the same session. That opens doors for smarter assistants, better content generation, and workflows that really fit how we think and work. For developers, businesses, and Google itself, this model sets the stage for a new wave of AI-powered tools.
If Gemini 3 works well in real-world use, it could redefine expectations around virtual assistants, creative tools, and search itself. Moreover, by reducing errors, improving reasoning, and integrating across tools (like Search and coding environments), Google is positioning AI not just as an assistant, but as something proactively helpful. That means the AI you engage with could become more capable, contextual, and tailored to you.
Why should I care? If you use AI tools, create digital content, or rely on search and productivity apps, Gemini 3 could noticeably shift your day-to-day experience. It’s not just a speed bump; it’s a broader upgrade in what Google’s AI can understand and produce.
- Better answers: With stronger reasoning and multimodal input handling, interactions can feel quicker, more natural, and more accurate.
- Smarter workflows: Whether coding, researching, or working on creative projects, the tools around you may feel smoother and more capable, cutting down on the small frustrations that slow you down.
- Platform shifts: As Google weaves Gemini 3 deeper into Search, Workspace, and other apps, expect familiar features to quietly evolve, even if you don’t notice the change right away.
In short, even if you don’t “see” Gemini 3 directly, you’ll likely feel its influence as it becomes the engine behind more of Google’s ecosystem. It builds on Gemini 2.5’s foundation but with sharper reasoning, better instruction-following, and more stable multimodal performance. Tasks that previously tripped up 2.5, like maintaining context or juggling multiple images, are handled more smoothly here, resulting in an upgrade that feels less like a version step and more like Google redefining how its AI assistant should behave.
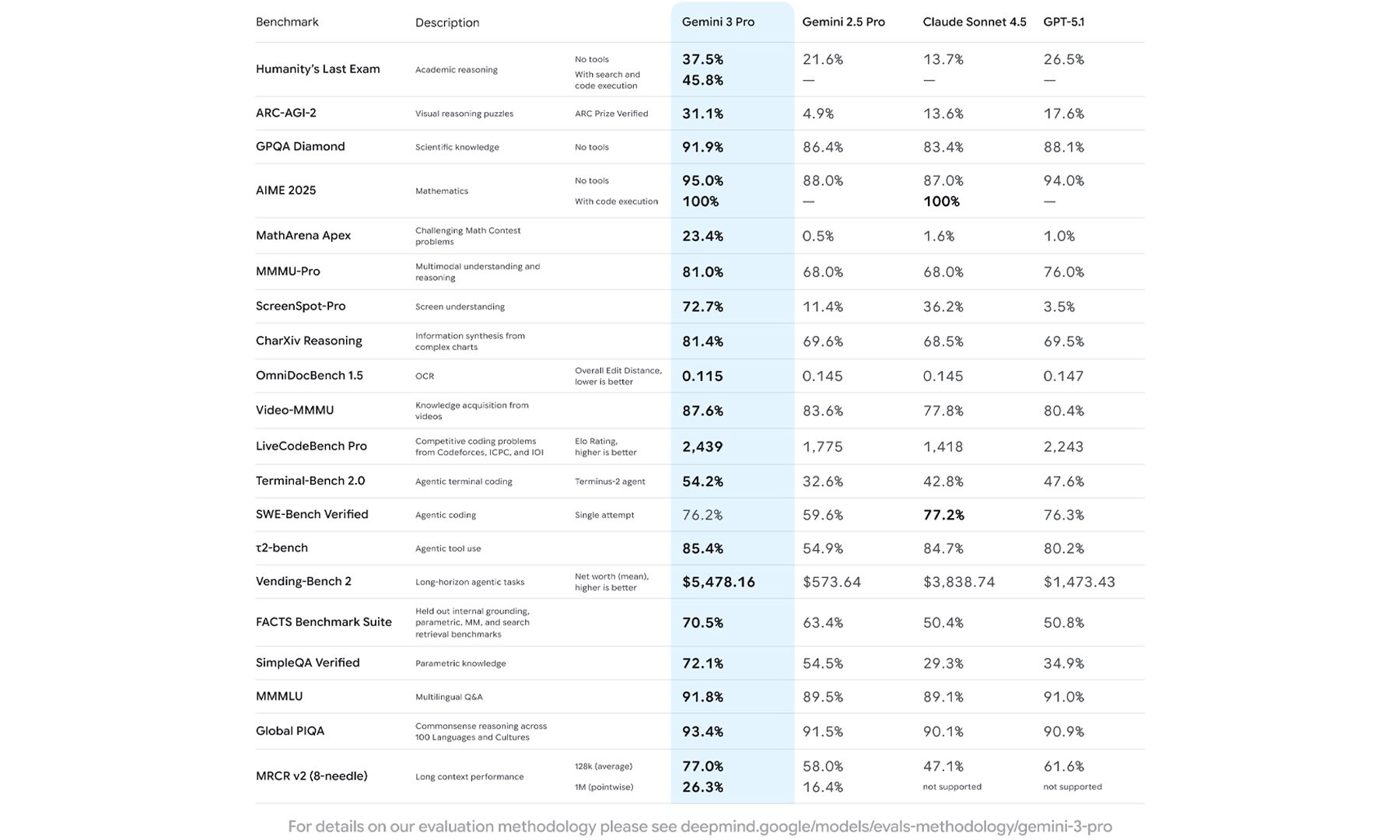
And here’s where things get even more interesting: Gemini 3 Pro isn’t just better on paper, but it’s also scoring noticeably higher across various AI benchmarks. These gains show up in areas like long-form reasoning, code generation, and complex multimodal tasks. In real use, that translates to fewer moments where the model loses track of what you’re asking, a higher chance of getting the answer you actually wanted, and more stable performance when juggling multiple files, images, or steps.
Okay, so what’s next? If you’re using the free version, you can start experimenting with Gemini 3 today, as it’s already live across the Gemini app and in AI Mode in Search. This means you can test its improved reasoning, multimodal input (text, images, etc.), and more intuitive prompts to see how it works for your daily tasks.
For Pro (and Ultra) users, there’s more in store: you’ll get access to the full Gemini 3 Pro model’s advanced capabilities (stronger reasoning, deeper context handling, richer multimodal responses) and soon the new “Deep Think” mode which is designed for the most complex workflows. All of this means that if you upgrade, you’ll experience a higher-tier version of Gemini that’s more powerful and responsive.


